

News and views from More Metrics

Using Petition Data to estimate the results of the 2024 General Election
Tuesday 2nd July 2024
Colin Stewart
General Election 2024 seat forecasts:
What makes the forthcoming general election particularly interesting from an analytical perspective is the number of organisations that are modelling the likely outcome. Even better, these organisations have been very open about sharing their data sources and methods in well written blogs and posts. It all makes for interesting and educational reading.
As a newbie to election modelling, I have had to grapple with concepts such as “multi-level regression and post-stratification modelling (MRP)” and the nuances of different “swing” assumptions that practitioners use in their models.
Published models all point to a large majority for Labour, but beyond that seat projections vary a lot. This topic was covered in a recent episode of Tim Harford’s Radio 4 programme “More or Less”, broadcast 26th June and I recommend giving that a listen. In this programme, they discuss how important swing assumptions are (alongside other things) in determining the wide range of seat projections from different MRP models. More or Less - Election claims and erection claims - BBC Sounds (13mins 40 secs onwards).
MRP models use large-scale polling and a set of demographic data to vary the swing based on the individual characteristics of residents in each constituency. Swing is therefore determined by a whole host of factors relating to individual demographics informed by up-to-date polling data. The polling data and modelling assumptions are unique to each polling organisation and as many contests are on a knife edge this gives rise to the wide differences in modelled seat projections under a first past the post (FPTP system).
Can petition data help improve forecasts? The More Metrics challenge:
While the seat projections vary a lot, there is one aspect of the modelling work done by the polling organisations where there is a lot in common. This is the choice of predictor variables used in their MRP models where most organisations use a very similar set of demographic variables. What has struck us at More Metrics is that no polling organisation, as far as we can tell, has included parliamentary petition data in their models as an input. This has got us thinking!
We know from our own analysis that parliamentary petition data leading up to an election is predictive of vote shares by party after the event. We have seen this with the 2019 election and for the Brexit vote.
We are therefore curious to see if petition data could be used in a forecasting model to good effect, and as a test we have developed a modified swing model that incorporates petition data. Swing models are nowhere near as sophisticated as the MRP approach but have a good track record at estimating overall seat predictions. What they don’t do particularly well is provide accurate seat by seat predictions, but that is not a primary concern for us.
In our method we use past election outcome data by parliamentary constituencies, combined with more recent petition data. Constituencies are clustered into segments based on previous voting patterns by party and petition signature rates. The petition data provides the recent insight (after the last election 2019) that could indicate a change of voting intention for each constituency at the forthcoming election.
Petition data used in our swing model:
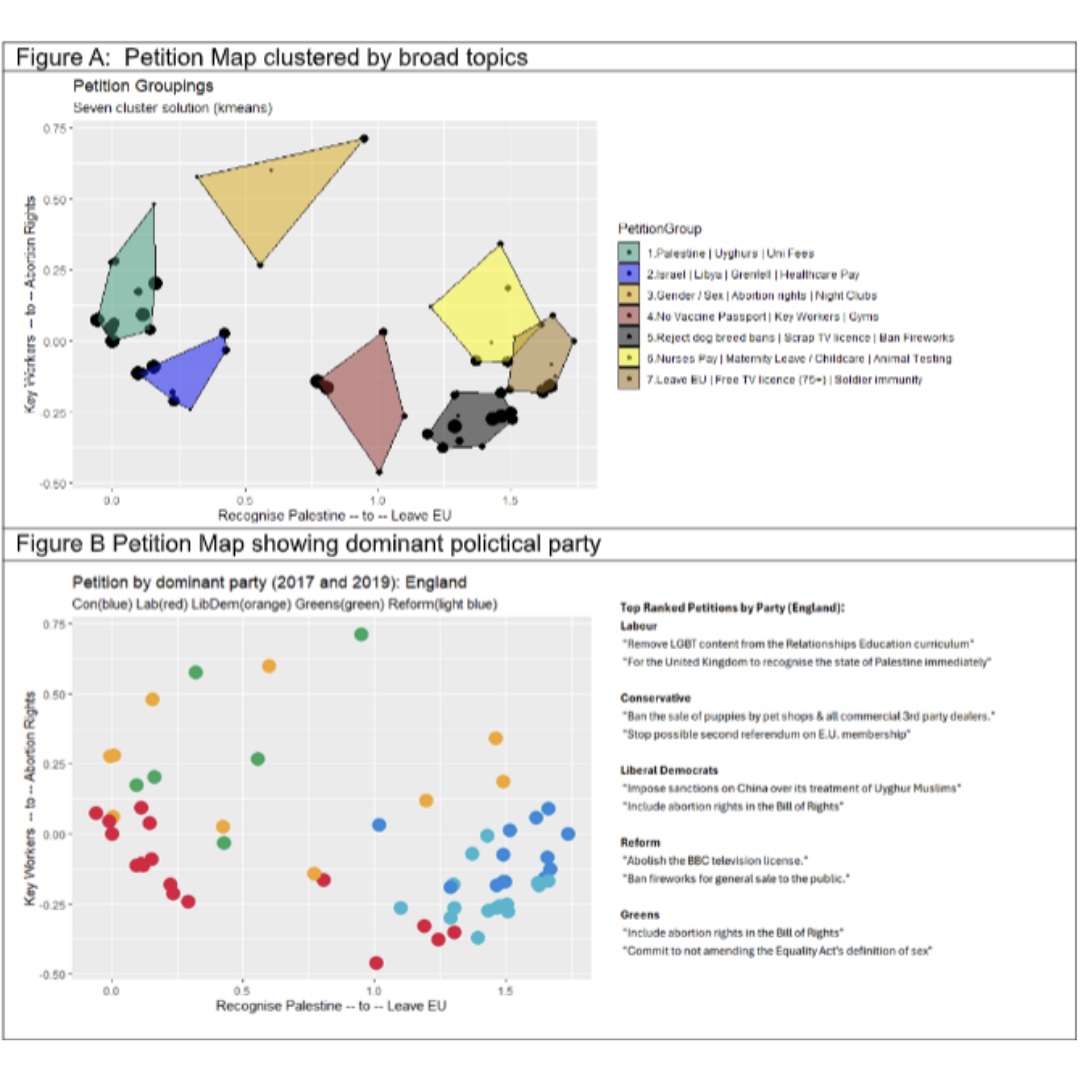
For this analysis we have selected more than 60 well-behaved petitions which represent a wide range of concerns. We use our own data reduction technique (petition mapping) to locate each petition in 5-dimensional space based on the correlations between petitions. Petitions that are strongly positively correlated to one another are near neighbours, those that are negatively correlated to one another are far apart. Figure A shows the petition map collapsed from 5 to 2 dimensions with the data oriented to minimise the out of plane values (for dimensions 3 to 5). We have clustered the petitions by broad topics to highlight the wide range of subjects these petitions cover. Point size is an indicator of average signature rates (ranked 1 to 5).
To demonstrate the potential usefulness of petition data in estimating voting intentions, we can calculate the average 2017 and 2019 vote shares for each petition from constituency election data weighted by normalised petition counts. This analysis reveals the dominant party for each petition, determined by the rankings of petition vote shares by party. The highest ranked party for each petition is selected, with the results indicating strong associations between certain topics and specific political parties.
Modelling Seat Projections Using Petition Data:
We employ a five-step process to estimate seat projections for England, Scotland, and Wales:
Combine Historic Data: Integrate historic constituency vote shares (2010 to 2019) with recent petition data and impute missing vote share values in historic data using random forests. This adjustment accounts for parties like Reform and the Greens, which are standing in almost all constituencies in 2024, unlike in previous elections.
Create Constituency Segments: Use k-means clustering to create constituency segments. The number of segments varies by country: England (50), Scotland (10), and Wales (5). The distribution of vote shares for England by cluster is shown in the appendix, Figure A.1. indicating distinct clusters with well-defined vote share estimates and relatively small inter-quartile ranges.
Apply Swing Curves: Apply swing curves to the clustered data to calculate new expected mean values for 2024 by party and by cluster. Our swing curves are detailed in the appendix, Figure A.2.
Calculate Individual Estimates: For each constituency, randomly assign a perturbation to its parent cluster x party mean value using the estimated standard error for each cluster x party vote share. To mitigate the impact of outliers, we use the averaged standard error for clusters by vote share, as shown in the appendix, Figure A.3.
Assign Seat Winners: Assign the party with the maximum vote share in each constituency as the seat winner.
The model is iterated 1,000 times (steps 3 to 5) with different national vote share estimates calculated from a set of chosen standard errors for each vote share average. The vote shares and standard errors used in our simulations are detailed in the appendix, Figure A.4.
Model Results:
Our model results are shown in Figure C and are broadly consistent with other estimates. We forecast that Labour will achieve a substantial majority with 481 seats out of 632 in Great Britain. The Conservatives will secure 76 seats, the Liberal Democrats 43 seats, the SNP 22 seats, Reform 7 seats, Plaid Cymru 2 seats, and the Greens 1 seat.
Appendix:
A.1. Cluster solution for England:
The data used for clustering includes 5 standardised variables. Two variables relate to petition data and three to vote shares for the main parties in each nation. K-means clustering applied to this data gives well defined clusters as can be seen from the example below for England (Figure A.1)
A.2. Swing assumption:
Data limitations mean that we have only looked at the changes in party shares between 2010 and 2019 (four elections giving three changes of share for each main party). There have only been a handful of examples in this time period where the party swings have been sufficiently large for them to be considered uniformly up or uniformly down. Nevertheless, even using these small number of examples we are able to calculate swing parameters that we use for our own modelling. We have derived two swing curves by vote share that differ depending on whether the swing is up (increase) or down (decrease). Figure A.2 shows
©More Metrics 2024 Making data local the results calibrated for an average swing of about 10%. The curves for different average swing values are pro-rated accordingly.
A.3. Calculation of individual constituency vote shares:
Each constituency belongs to a parent cluster (see A.1 for more details). The vote shares for each party in each constituency are calculated from the mean share for the cluster x party combination after applying a swing, with a random perturbation added using a standard deviation (sd) value. To reduce the impact of outliers in historic data that could affect the sd value for a particular cluster x party, we use a smoothed sd values by vote share (see Figure A.3 )
The national share values used in our modelling have been taken from various poll tracker sources including the BBC and Wikipedia. We have done our own apportionment of GB / UK values where appropriate to back calculate values for England from published values for Wales, Scotland and GB / UK.
We have added some relatively small perturbations to these national values assuming a normal distribution and a sampling size of 1000 for each cell. We have randomly varied the values for party x country independently when running each iteration.
The specific values used (as at 1/7/2024) are detailed below, Figure A.4.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}